
Simple Subtitle extractor using OpenCV and Python
With emphasis on extracting subtitles from old movies


Several years ago I worked on extracting Machine Readable Zones from passports and ID cards. While researching the issue a post from pyimagesearch popped up. It turned out to be an excellent starting point. Afterward, another project idea came up that could be solved using a similar approach: automatic subtitle extraction from burnt-in subtitles with emphasis on older movies. While modern movies have crisp and clear subtitles this is not the case with old movies.
I never fully finished the project as my curiosity itch was sufficiently scratched, but if you like to poke and improve it you can find the full code as always on GitHub. Theres a lot that could and should be improved as this was basically a proof of concept script. The code is pretty well documented so this could be seen as a basic intro to the project and in the broad strokes of how it works. For more details check out the source code.
The subtitle extraction relies on subtitles being static while the background moves.
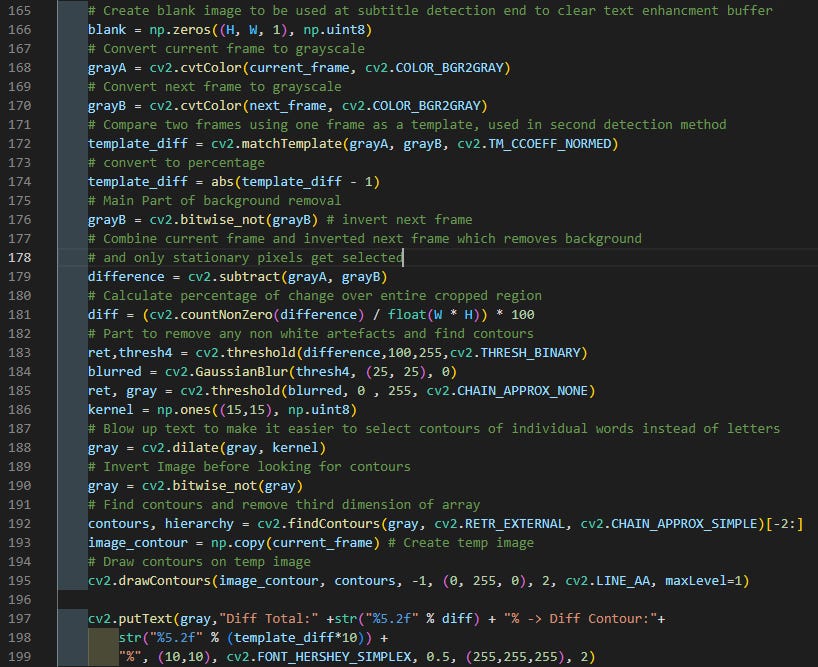
The approach takes two successive frames and inverts one to get only pixels that don't change from one frame to the next. If a change in the background is not big there is a possibility of having leftover pixels that are not part of the subtitle so additional processing is needed.
Most subtitles are white so they are isolated and other colors removed. Then, the remaining pixels are enlarged creating blobs. This enables subtitles to be grouped and isolated white islands removed under the presumption that they are not part of the subtitle font.

Subtitles from old movies are all over the place and that’s why a “buffer” is added where when a large change is found any subsequent frame is added to the last one after processing. This improves the definition of found text but will introduce ghosting from none filtered effects like in the example above. In that example, a candle flame is moving behind the subtitles but is not filtered out and the image that will be sent to OCR contained ghosts of that flame moving for the duration of the subtitle.
Update: After revisiting this code I see another approach where blown-up text can be used as a template to subtract from the background. This could be a much better approach. I will try when I get a chance and if it turns out true will update it.
Next, we need to detect if a subtitle is on the screen and when it ends as that information is needed when creating a subtitle (.srt) file for translation or playback.
There are two different ways change is detected. First is if the selected region comes to abrupt change is difference between two frames. The same approach is used to detect the start and stop of individual subtitle showing on the screen. The next approach is counting the number of blobs detected. This approach is better but has serious disadvantages. There are a lot of occasions that subtitles don’t have space between showing up on the screen and when enlarging the subtracted subtitles from the background to get them to group there is a high possibility that one subtitle could not be differentiated by the script as a new subtitle. Combining the two approaches could have solved it but I chose to separate them for testing and did not combine them afterward.
After we get our cleaned-up image of a subtitle we can send them to Tesseract-OCR, display it and save the output to the .srt file.

The first line in .srt is an index of the subtitle following is the timecode and the next is the subtitle itself.
6
0:00:13,440 --> 0:00:15,320
Dođite. Budite oprezni.
-Je li g. Fallon ovdje? -Jest.
Note: Installation of Tesseract under Linux is simple and there are many tutorials about it, on Windows tesseract needs a little coaxing. First, go to UB Mannheim, they hold precompiled x86 binaries for tesseract and download the one you like, usually the newest is the best bet, and install it. Remember where you installed it to.
To interact with tesseract you could write your own command prompt output pipe, one is included in the code, or just use pytesseract.
pyTeseract needs to be configured by editing tesseract_cmd in pytesseract.py which can be usually found in where ever you installed your Python, like x:\Python3\Lib\site-packages\pytesseract\. There edit pytesseract.py and add a path to where you installed tesseract, something like: tesseract_cmd = 'D:\\TesseractOCR\\tesseract'
The full code as always can be found on GitHub. There are two versions of the script. find_subtitl.py is an alternate version with a completely different control scheme and detection method but it turned out to be too finicky. But could be interesting to someone so it’s also in the repository.
To do a test run several test files are provided and you can run them
python.exe findsub_in_video.py -t 0.9 -v test.mp4 -d 0 -o test.srt
As shown in the first picture there are different parameters you can adjust and play around with to see how they affect the outcome.