



A couple of weeks ago I received my invite to check out DALL-E 2. There are many reviews and in-depth tests of DALL-E 2 all over the place and it definitely deserves it. The technology behind it is beyond amazing. This is just my quick take on it.
DALL-E 2 uses GPT-3, a Generative Pre-trained Transformer 3 language model that uses deep learning to produce human-like text but in the case of DALL-E, it generates images based on user input. Input can be text or user-submitted images on which additional manipulations can be made.
Or, simply put, you write what you want to see and the AI tries to generate that image. Simply fantastic, and not a little Sci-Fi like. Just a few years back such capability was the stuff of wet dreams of computer scientists.
As of the time of writing DALL·E team just announced that they are entering Beta testing and will invite additional 1 million users to use DALL-E. They also reduced the number of generated images to 4 from a single prompt and introduced a credit system with 50 free credits during their first month of use and 15 free credits every subsequent month. Each credit can be used for one original DALL·E prompt generation. All to reduce strain on their systems as more and more people are introduced to it. There was also a change in permissions as now images can be used to commercialize the images they create with DALL·E, including the right to reprint, sell, and merchandise with users getting the full usage rights.
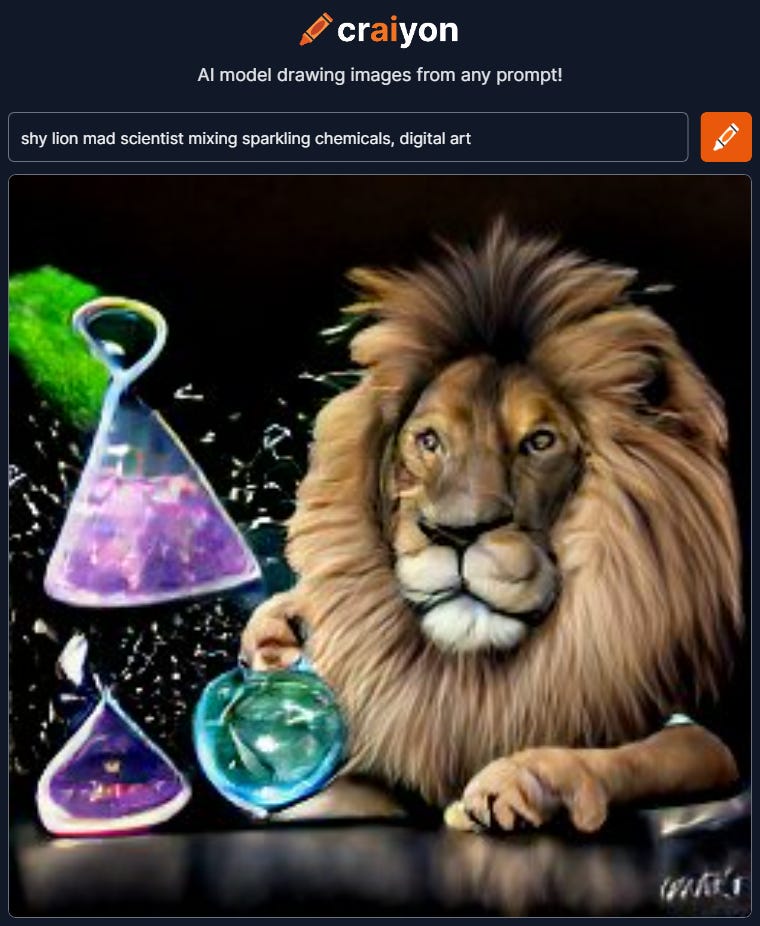
“shy lion mad scientist mixing sparkling chemicals, digital art”

This image did not exist before it was made by artificial intelligence. Mind blown 🤯
While doing some search I found crAIyon, formerly known as dall-e mini / mega. Its a much smaller model, about 2Gb for mini and 10Gb for mega version, and could be run on some high-end systems with enough memory.
Large, monstrously large AI models are all fine and good but they are relegated to server farms. And, I like to see that there is a concerted effort from the community to bring the same capability to desktop. Similar to what GPT-Neo did with regards to GPT-3.
I tried the same input as the above one for DALL-E 2 and got the image below. It’s not as refined as DALL-E but it got the gist of it.
If you didn’t know I’m interested in Mosaic generation and did a little test if AI understood and was interested if it could generate image mosaic and was surprised. It did understand what I wanted, it tried to generate it but the model has some limitations in face generation so they did not fully generate tiles with faces.
“mosaic of small images of faces that make up a larger face”

“image of a young woman made out of smaller images, mosaic”

I really don't know how I feel about this. It’s like living in a Sci-Fi novel that is still being written. And it’s at the same time terrifying and exhilarating.